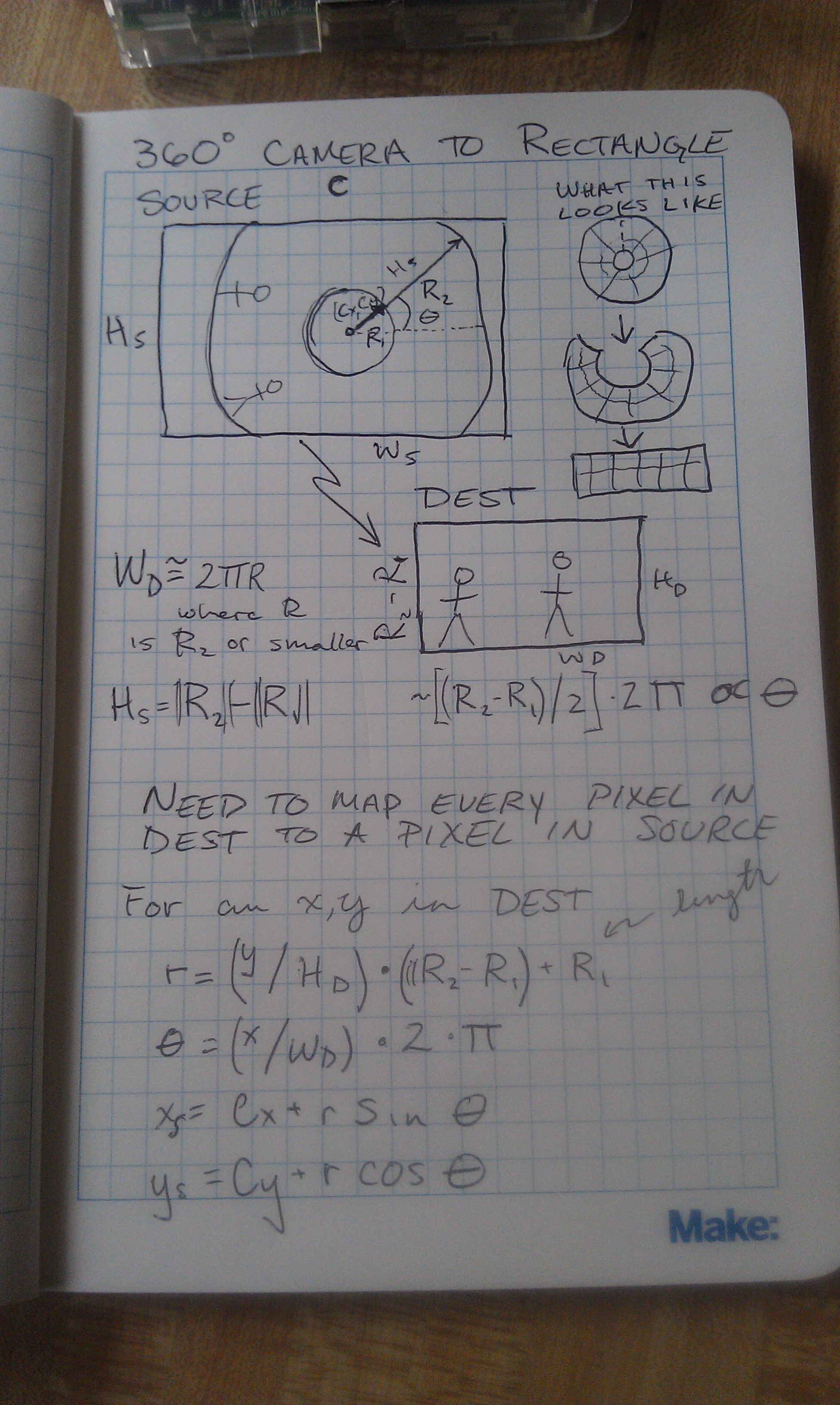
The entire process as one big image.
I was challenged to see if I could create 360 degree view panoramas from a series of fish eye images taken at right angles to one another working from this tutorial. I modified the code from my 360 lens dewarping project to create the code for this project which you can check out here. There are roughly two types of fisheye images, circular fisheye lens that map a sphere onto the image plane, and full frame fisheye lens that map the input image to the entire rectangular image plane. The data I was working with was from a circular fisheye, which is significantly easier to reason about.
There are a couple of different ways you can approach the problem of fisheye lens dewarping. The first, and probably more robust approach is to develop a camera lens model that accurately represents the fish eye lens distortion, and apply that lens dewarping to the image. In the absence of a calibration data, particularly for full frame fisheye’s, you would then need to manually tune the camera model parameters to dewarp the image, or use some of the image data to get a back of the envelope approximation of the camera parameters. The second, and in my opinion the easier, albeit slightly less robust approach, is to create a mapping from the output image pixels in terms of phi and theta in a circular coordinate system, and map that to pixels in the input image. The basic idea is that in the output image each pixel represents some steradian on the input image. The best way to think about a steradian is as a “pixel” on the sphere, or the square mapped out by latitude and longitude lines. Each steradian then maps to a point on the image plane, which you can calculate by doing a spherical to Cartesian conversion and dropping the value that is in the normal to the image plane.

Dewarped image on the left and input circular fisheye image on the right.
For example, in my code, I first create an output image and assume each x and y position on the image maps to somewhere roughly between 0 and 180 degrees (0,pi) for both phi and theta. In my model the direction pointing straight out of the camera is called y, so I then do a spherical to Cartesian conversion assuming a unit sphere. Since the unit sphere is at the origin, I shift the sphere and rescale it to be of unit length, and then multiply the result by the input image dimensions. An easier way to think of it is this:
Destination image pixel (X,Y) –> scale to unit length –> convert to between zero and pi –> do spherical to Cartesian conversion –> rescale to get values between 0 and 1 –> multiply by the input image dimensions to get input pixel (X,Y).
The map is a bit tedious to create, but once you have it, OpenCV can really quickly push pixels around and give you a result.

Panorama dewarped from four fish eye images.
The next step was to do the panorama stitching. To do this I first matched ORB keypoint between two successive pairs of images. Since I knew the images were vertically aligned, all I needed to calculate was the x value that is the horizontal offset. To do this I used the median x difference between the two sets of points (the median in this case acts as a poor man’s RANSAC to remove outlier matches). I then used this x offset to construct an alpha mask that I could use to smoothly blur the two images together. I played with this for a little while and I found a nonlinear mapping seemed to work a lot better. There are some problems with the images as they don’t seem to be taken at the exact same time, but for a half a day’s worth of work I am very pleased with the results.