

My friend talked me into participating in the HackTheMuseum hack-a-thon at the Henry Ford Museum during the Detroit Maker Faire. The hackathon was intended to feature a new API for the museum’s digital assets. We did a recon trip the week before the hack-a-thon and outlined what we thought would make a great app. The newer exhibits at the Henry Ford are actually really slick. You can search through the physical and digital collection and curate collection via large touch screens installed in the museum for later retrieval at home. After our recon trip we distilled a few key design elements that we wanted in our app.
- We specifically didn’t want to duplicate the functionality of the existing infrastructure. Given the time constraints we really couldn’t do it better.
- We noticed a couple of visually impaired visitors who could of benefited from audio tours. The Henry Ford Museum doesn’t currently have audio tours like a lot of other tours.
- We didn’t want to write a mobile application. People go to museums to experience artifacts they can’t see anywhere else. The museum should be for enjoying these objects, not staring face-down into a cell phone or iPad.
- The museum sees a wide variety of visitors. Visitors of all ages, nations, ages, races, capabilities, and socio-economic status. We didn’t want to assume that our users had expensive cellphones with equally expensive data plans, or the tech savvy to operate them. My experience is that my parents, the kids I couch, and my family can all operate mp3 players and MMS text messages. We wanted to stick to a medium that could see wide adoption.
- Every good idea we had some sort of mapping element which really isn’t available in the Henry Ford Museum API. Every experience we could think of started with, “Where is cool thing X at the museum”. Having a map is an indispensable part of the museum experience. There is simply too much to see in one day, you pick the stuff that really interests you.
The night before the hack-a-thon I thought up an idea that I pitched to the team. The idea was to create custom maps and audio tours for the museum and then deliver them via a diversity of mediums. Have a smartphone? Great, here is a map image or dynamic map and a SoundCloud link / dynamic HTML audio. Have a dumb phone? Get the content delivered via SMS message. Are you a teacher who wants to customize a visit? Awesome, dumb mp3 players are dirt cheap, you can get a set for a classroom for half the price of one iPod. You can load up a tour and hand it over to the kids.
When the hack-a-thon started we decided to narrow our focus to a single exhibit so we could do the mapping and build out the content at least reasonably well. We needed to manually determine the positions of a bunch of exhibits. I started out by figuring out how to do the text to speech. My first task was to get the data I wanted to put in the tour from the museum API. After a bit of massaging I was able to pull out the data I wanted from the API. I settled on the exhibit location descriptions, display titles, the various abstracts/copy about the artifacts, and the thumb nail images. I wrapped this into a function that would pull down this info based on an id number. I then made another function that would stitch together various bits of text into a cohesive body text.
Python is my preferred hacking language of choice so I needed to figure out how to take the large body of text I could generate and spit it out as text to speech. There is pyttsx for text to speech, but it only outputs to the sound card. You could probably snag the raw wav data with a bit of hacking but that I would take awhile. There are also a bunch of APIs but I figured I could do decent job locally, also I had hopes to compose the text to speech with audio from the API but that never materialized. I decided to just use the python subprocess module to call the espeak linux command line utility to generate the speech wav files. I then ran ffmpeg over the raw wav files to convert them to Mp3. Finally I used the SoundCloud API to upload the output WAV file. Pretty? No, but it worked, that’s why they call it a hack-a-thon.
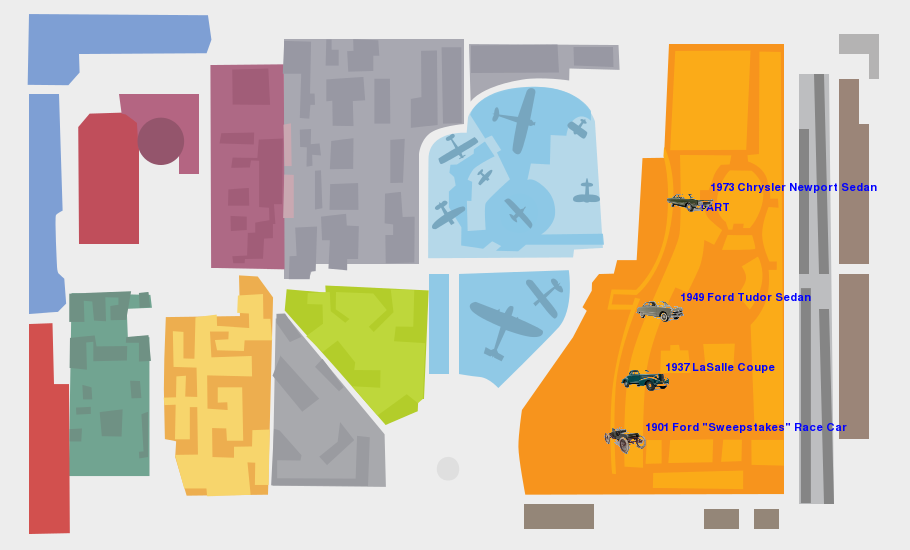
An example “hacked” map of a custom museum tour.
With the sound data taken care of I then proceeded to work on mapping. I had already pulled down the exhibit thumbnails so I all I had to do to position them on map was to map the exhibit location to the map. I just tossed our hand rolled map points into a python dict keyed on ID and made it a class member. Serious duct tape coding to be sure, in real life the museum would provide this info or you could toss it in your favorite data store. I then used a bit of SimpleCV magic to build alpha maps of the thumbnails and blit them onto the map. I also played with generating an animated gif of the the tour, but a lot of gifs were really big even after I ran them gifsicle. Gifs don’t render on old cell phones and imgur kept shitting the bed on big files so I cut it.
.@kscottz here is your Henry Ford #HackTheMuseum Audio tour: http://t.co/uJ36o7yEqE and map http://t.co/S46tJNPR75
— Katherine A. Scott (@kscottz) July 28, 2013
To deliver the content I used the Twitter API and the Twilio API. Twilio delivers data via SMS but not MMS so I was also hoping to use the MoGreet API to deliver images and sounds directly but I just plain ran out of time. I had some bits of code for the Twilio API so I just stuck with it. The last step was to link all of the front end UI with the back end bits. To do this I just used the python BaseHTTPRequestHandler and HTTPServer.
Like I said, it isn’t pretty but it works. That is why they call it a hack-a-thon. You can check out the code on Github. The Henry Ford Museum Asset API is only available within the museum so I grabbed a screencast video (sorry no audio). You can also hear some of the auto generated audio above.
We did reasonably well all things considered. We tied for second place at the hack-a-thon and I got a swell hard hat and few tickets to the Henry Ford Museum and Greenfield Village. The entire team did a great job. It was our first hack-a-thon ever, and we were reasonably front end heavy, and I have a minimal back end experience.

